- Обучение
- Поступление в ЗФТШ
- О ЗФТШ
- Учителям
- Лекторий
-
Курсы
- Заочное отделение
- Очное отделение
- Очно-заочное отделение (Факультативы)

Всякий текст состоит из символов - букв, цифр, знаков препинания и т. д., - которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов - и вовсе неприемлем. Используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел - кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются кодовые таблицы символов, в которых для каждого символа устанавливается соответствие между его кодом и изображением. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил ASCII (American Standard Code for Information Interchange) - американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации. В нём используется `7`-битное кодирование: общее количество символов составляет `2^7=128`, из них первые `32` символа - «управляющие», а остальные - «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
|
Cимвол |
Действие |
Английское название |
|
№7 |
Подача стандартного звукового сигнала |
Beep |
|
№8 |
Затереть предыдущий символ |
Back Space (BS) |
|
№13 |
Перевод строки |
Line Feed (LF) |
|
№26 |
Конец текстового файла |
End Of File (EOF) |
|
№27 |
Отмена предыдущего ввода |
Escape (ESC) |
К изображаемым символам в ASCII относятся буквы английского (латинского) алфавита (заглавные и прописные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки ASCII приведён в таблице.
|
Символ |
Десятичный код |
Двоичный код |
Символ |
Десятичный код |
Двоичный код |
|
Пробел |
`32` |
`00100000` |
`0` |
`48` |
`00110000` |
|
`!` |
`33` |
`00100001` |
`1` |
`49` |
`00110001` |
|
# |
`35` |
`00100011` |
`2` |
`50` |
`00110010` |
|
$ |
`36` |
`00100100` |
`3` |
`51` |
`00110011` |
|
`**` |
`42` |
`00101010` |
`4` |
`52` |
`00110100` |
|
`+` |
`43` |
00101011 |
5 |
53 |
`00110101` |
|
, |
`44` |
`00101100` |
`6` |
`54` |
`00110110` |
|
`–` |
`45` |
`00101101` |
`7` |
`55` |
`00110111` |
|
. |
`46` |
`00101110` |
`8` |
`56` |
`00111000` |
|
/ |
`47` |
`00101111` |
`9` |
`57` |
`00111001` |
|
`A` |
`65` |
`01000001` |
`N` |
`78` |
`01001110` |
|
`B` |
`66` |
`01000010` |
`O` |
`79` |
`01001111` |
|
`C` |
`67` |
`01000011` |
`P` |
`80` |
`01010000` |
|
`D` |
`68` |
`01000100` |
`Q` |
`81` |
`01010001` |
|
`E` |
`69` |
`01000101` |
`R` |
`82` |
`01010010` |
|
`F` |
`70` |
`01000110` |
`S` |
`83` |
`01010011` |
|
`G` |
`71` |
`01000111` |
`T` |
`84` |
`01010100` |
|
`H` |
`72` |
`01001000` |
`U` |
`85` |
`01010101` |
|
`I` |
`73` |
`01001001` |
`V` |
`86` |
`01010110` |
|
`J` |
`74` |
`01001010` |
`W` |
`87` |
`01010111` |
|
`K` |
`75` |
`01001011` |
`X` |
`88` |
`01011000` |
|
`L` |
`76` |
`01001100` |
`Y` |
`89` |
`01011001` |
|
`M` |
`77` |
`01001101` |
`Z` |
`90` |
`01011010` |
Хотя в ASCII символы кодируются `7`-ю битами, в памяти компьютера под каждый символ отводится ровно `1` байт (`8` бит). И получается, что один бит из каждого байта не используется.
Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только текста, состоящего из английских букв. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII-кодировки, в которых применялись однобайтные коды символов; при этом первые `128` символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со `128`-го по `255`-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более `127`.
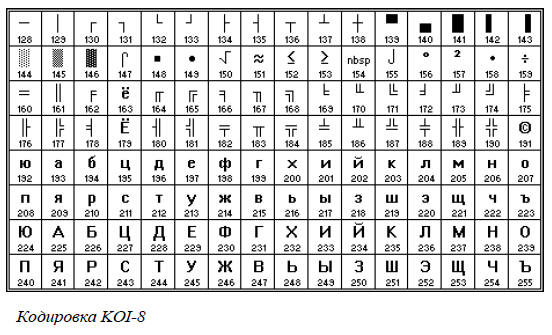
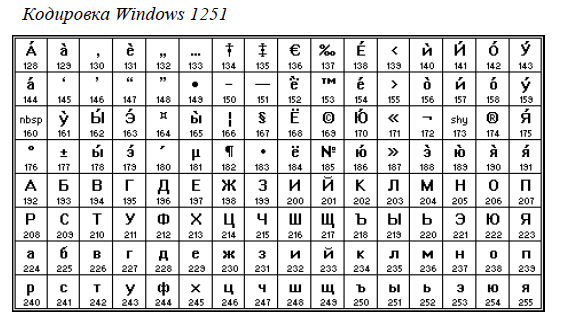
Для русского языка наиболее распространёнными являются однобайтовые кодовые таблицы СР-`866`, Windows-`1251`, ISO `8859-5` и КОИ-`8`. В них первые `128` символов совпадают с ASCII-кодировкой, а русские буквы помещены во второй части таблицы (с номерами `128-255`), однако коды русских букв в этих кодировках различны! Сравните, например, кодировки КОИ-`8` (Код Обмена Информацией `8`-битный, международное название «koi-`8`r») и Windows-`1251`, фрагменты которых приведены в таблицах на странице `13`.
Несовпадение кодовых таблиц приводит к ряду неприятных эффектов: один и тот же текст (неанглийский) имеет различное компьютерное представление в разных кодировках, соответственно, текст, набранный в одной кодировке, будет нечитабельным в другой!
Однобайтовые кодировки обладают одним серьёзным ограничением: количество различных кодов символов в отдельно взятой кодировке недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993-м году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы всех языков мира.
В Unicode на кодирование символов отводится `32` бита. Первые `128` символов (коды `0-127`) совпадают с таблицей ASCII, все основные алфавиты современных языков полностью умещаются в первые `65536` кодов (`65536=2^16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже - некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, `16`-битная версия Unicode, в которую входят все современные алфавиты; эта часть Unicode называется базовой многоязыковой страницей (Base Multilingual Plane, BMP).
